Als die Entwickler eine Begründung brauchten, warum sie das erste UNIX auf eine andere, größere Maschine portieren sollten, war die Textverarbeitung ein ausschlaggebendes Argument. Mit der Zeit entwickelten sich zum einen die Tools, um Text zu erstellen, zu formatieren und auf Fotosatzmaschinen auszugeben, und zum anderen wurden im System selbst zur Konfigurierung viele Textdateien benutzt.
Verwendet man Textdateien zur Konfigurierung, dann ist die Anpassung mit Hilfe eines einfachen Texteditors möglich. Andere Betriebssysteme haben davon eine Menge gelernt.
Texte tauchen in Computerprogrammen und Systemen fast an jeder Ecke auf. Die Konfigurierungsdateien sind bei DOS z. B. "config.sys" und "autoexec.bat" Textdateien. Auch die Führung des Benutzers am Bildschirm benötigt Texte, und jeder Dateiname ist ebenfalls ein Text.
Gleich zwei der im ANSI-Standard definierten Informationsdateien beziehen sich auf die Arbeit mit Texten und Buchstaben: die string.h und die ctype.h, die sich mit der Klassifikation von Buchstaben (oder allgemeiner: Zeichen) beschäftigt.
Die Besprechung der Arbeit mit Texten beginnt bei der internen Darstellung in C. Danach kommt die programminterne Bearbeitung von Texten, und schließlich wird mit Texten in Dateien gearbeitet.
![[Textkonstante, anonym]](tanokon.gif)
Bild 5-1: Arbeiten mit Textkonstanten
Eine Textkonstante wird in Anführungszeichen eingeschlossen. Damit wird dem Compiler mitgeteilt, daß er einen anonymen Text anlegen soll. Der Text wird dem Aufbau entsprechen, den C erwartet. Das Ende des Textes wird mit einer Kennung versehen, der binären "\0". Dies ist ein Zeichen, bei dem alle Bits auf "0" gesetzt sind. Texte (oder engl. strings) können daher beliebig lang werden. Andere Sprachen geben im ersten Byte die Länge des Textes an und begrenzen damit die maximale Textlänge auf 255.
C unterscheidet zwischen Zeichenkonstanten und Textkonstanten. Eine Textkonstante erkennt man an den einfachen Hochkommta, betrifft immer nur ein einzelnes Zeichen und kann daher in einer char-Variablen gespeichert werden. Gibt man dagegen einen Text in Anführungszeichen an, der nur aus einem einzelnen Zeichen besteht, dann fügt der Compiler automatisch die Endekennung hinzu. Zum Speichern dieses Textes würden mindestens zwei char-Variablen benötigt. Texte legt man daher in Feldern aus Zeichen (char []) ab.
![[Text vs. Zeichen]](tstring1.gif)
Bild 5-2: Der Unterschied zwischen Zeichen und Texten
Ein Sonderfall ist der leere Text. Eine Textkonstante ohne Nutzdaten besteht zumindest aus der Schlußkennung. Von diesem einen Byte kann der Compiler auch eine Adresse gewinnen. In den Funktionen, die mit Texten arbeiten, sind leere Texte ein durchaus üblicher Parameter. Ein leerer Text ist also nicht "Nichts".
Will ein Programmierer eine Variable für Texte aufbauen, muß er ein Feld aus Zeichen anlegen. Bei Bedarf kann es auch mit Hilfe einer Textkonstanten initialisiert werden.
![[Zeichenfeld als Text]](tfelvar.gif)
Bild 5-3: Textvariable als Feld von Zeichen
C kennt Texte nur als Konstante, nicht aber als Datentyp. Damit kann man innerhalb der Sprache keine Variablen für Texte anlegen und keinerlei Operationen mit Texten ausführen. Das Hilfsmittel für alle Fälle, die nicht Teil der Sprache sind, ist immer der Aufbau einer Funktion oder einer Funktionsbibliotek.
In der Standardbibliothek werden daher alle grundsätzlichen Operationen mit Texten mit Hilfe eines Satzes von Textbearbeitungsfunktionen nachgebildet.
Felder aus Texten werden aus zweidimensionalen Feldern aus Zeichen aufgebaut.
![[Textfeld]](ttexfel.gif)
Bild 5-4: Ein Feld aus Texten
Felder werden in C bei Übergaben an Funktionen nicht als Wert übergeben. Die mögliche Größe der Felder würde zu einer Verschlechterung der Laufzeit führen. Man übergibt statt dessen einen Zeiger auf das erste Feldelement. Dieser Zeiger beschreibt zusammen mit der Endekennnung den Text für die gerufene Funktion.
Das bekannteste Beispiel für Textübergaben könnte "printf()" sein. Der erste Parameter ist immer ein Text, der als "char *", als Zeiger auf char, übergeben wird.
Statt eines Parameters kann man auch Zeigervariablen anlegen und sie mit einer Adresse eines Textes füllen. Im Beispiel wird eine Zeigervariable vom Typ Zeiger auf char angelegt und mit der Adresse einer anonymen Textkonstanten initialisiert. Ein Problem ergibt sich hier bei einer möglichen Verwendung der Variablen. Wird sie überschrieben, kann der Text nicht mehr gefunden werden. Er hat ja selbst keinen Namen und war nur über den Inhalt der Zeigervariablen bekannt. Dieser Fall wird selten verwendet.
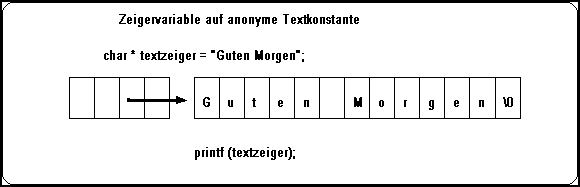
Bild 5-5:Zeigervariable für Texte
Ein häufigerer Anwendungsfall ist ein Feld aus Zeigern auf Texte. Felder haben die angenehme Eigenschaft, daß man schnell mit Hilfe eines Index auf den Inhalt zugreifen kann. Eine Tabelle setzt also von einem ganzzahligen Index auf einen Text um. Dies wird häufig verwendet. Denken Sie nur an Fehlernummern, die in Klartext ausgegeben werden sollen. Oder denken Sie an die Parameter des Hauptprogramms, die ebenfalls über ein Feld aus Zeigern übergeben werden.
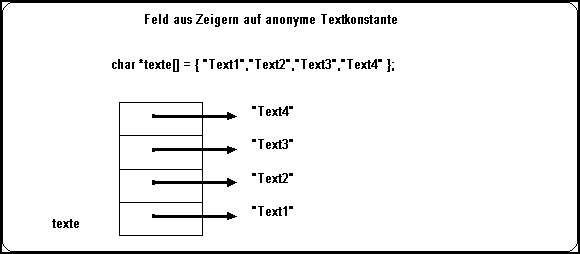
Bild 5-6: Feld aus Zeigern auf Texte
In jedem C-Programm, das unter einem Betriebssystem läuft, erhält die Funktion "main()" zwei Argumente. Das erste ist der Wortzähler der Aufrufzeile, und der zweite ist ein Feld aus Zeigern auf die einzelnen Worte.
![[Parameter Übergabe]](argvp.gif)
Bild 5-7: Feld aus Zeigern auf Texte
Mit diesen beiden Parametern kann nun ein Programm auf die Argumente der Kommandozeile zugreifen. Zu beachten ist dabei, daß die Parameter argc und argv selbst nicht verändert werden, um in möglichen späteren Programmteilen unverändert benutzt werden zu können.
Bild 5-8: Argumentenzugriff mit Index
Die Argumente bestehen nur aus dem Programmnamen, Optionen, die mit einem "-"-Zeichen oder unter DOS mit "/" eingeleitet werden sowie Dateinamen. Eventuelle Umleitungsaufträge ("<,>, >>, <<") werden von der Aufrufumgebung bearbeitet und gelangen nicht zum Programm. Man sagt daher auch, daß der Umleitungsmechanismus für das Programm transparent ist.
Es gibt zwei Methoden, auf alle Argumente zuzugreifen. Falls der Programmierer an das übergebene Feld denkt, ist ein Zugriff mit einem Index und einer for-Schleife sinnvoll.
Der gleiche Zugriff kann auch mit Hilfe einer while-Schleife formuliert werden. Das Abbruchkriterium liefert dabei der letzte gültige Eintrag in der Argumenttabelle, der immer NULL enthält. Die Schleife greift mit Hilfe eines Zeigers auf den Inhalt des Feldes zu. Da wir wissen, daß Felder per Zeiger übergeben werden, kann der Parameter auch als Zeiger auf Zeiger auf char definiert werden. Der Zeiger zeigt auf das erste Element im Feld, das seinerseits wieder einen Zeiger auf char beinhaltet.
Um zu vermeiden, daß ein Parameter verändert wird, wurde ein Hilfszeiger eingeführt und in der Schleife mitgeführt.
Bild 5-9: Zugriff auf Argumente mit Zeiger
NULL wird auch in der stdio.h definiert, size_t auch in den Dateien stdlib.h und stddef.h.
Man kann die Funktionen unterteilen in:
Es gibt häufig zwei Versionen der gleichen Funktion. Die eine setzt voraus, daß der Pufferbereich für den Zieltext groß genug ist und prüft daher die Länge nicht. Die zweite Version wird eine explizite Längenangabe als Parameter erwarten. Diese Version ist dann geringfügig langsamer als die erste.
In vielen Fällen arbeitet man in Programmen mit Texten mit bekannter Größe. Dann kann die erste Version verwendet werden.
#include <string.h>
void *memcpy (void * zielp, const void *
quellp, size_t n );
void *memmove (void * zielp,const void *
quellp, size_t n );
char *strcpy (char * zielp, cconst char *
quellp);
char *strncpy (char * zielp,const char *
quellp, size_t n );
Die Funktionen, die mit mem... beginnen, kopieren einen Speicherbereich, der aus einem Feld aus char besteht. In C gibt es keine kleinere Speichereinheit als char. Daher ist sizeof (char) immer eins.
Die Funktion memcpy() erwartet, daß Ziel- und Quellbereich sich nicht überdecken. Sollte es doch der Fall sein, ist das Ergebnis nicht definiert. Der Rückgabewert zeigt stets auf den Zielbereich, so daß das Ergebnis möglicherweise in einem anderen Funktionsaufruf gleich weiterbearbeitet werden kann.
Um die Beschränkung aufzuheben, daß Ziel und Quelle getrennt sein müssen, wurde "memmove()" eingeführt. Diese Funktion verhält sich so, als würde man zuerst den gesamten Zielbereich in einen Puffer schreiben und dann aus diesem Puffer heraus den Zielbereich füllen.
Vielleicht fällt Ihnen die Verwendung von typlosen Zeigern auf. Diese Funktionen werden auch in der Speicherverwaltung benutzt, wo es auf einen allgemein verwendbaren Zeiger ankommt.
Beide Funktionen kopieren genau so viele Zeichen, wie die Anzahl festlegt.
Bild 5-10: Kopieren einer Strukturvariablen mit "memcpy()"
Ein anderes Verhalten zeigen die beiden strcpy()-Funktionen. Sie berücksichtigen eine Endekennung und realisieren so den Textbegriff in C. Beide kopieren solange, bis eine Endekennung erkannt wird. Bei strncpy() gibt es eine zusätzliche Obergrenze für den Kopiervorgang. Die Zahl gibt die maximal mögliche Zeichenzahl an, die kopiert werden kann.
Bild 5-11: Kopieren von Texten
Hier kann sich ein Fehler einschleichen. Die str..()-Funktionen kopieren normalerweise die Endekennung mit, so daß das Ergebnis z. B. direkt in einer printf()-Funktion weiterverarbeitet werden kann.
Bild 5-12: Kopieren mit Längenbegrenzung
Bricht der Kopiervorgang aber an der Obergrenze ab, ist möglicherweise die Endekennung nicht mit kopiert worden, so daß dann das Ergebnis nicht dem Aufbau eines Textes in C entspricht.
In allen Fällen muß der Programmierer dafür sorgen, daß der Zielbereich groß genug ist und sich mit dem Quellbereich nicht überschneidet. Bei Überschneidung ist das Ergebnis nicht definiert. Schlimmer ist die Situation, falls der Zielbereich nicht ausreichend groß gewählt wird.
Da keine Überprüfung der Grenzen stattfindet, kann ein fehlerhafter Zielbereich zum Überschreiben anderer Daten führen. Besonders bei lokalen Variablen, die zumeist am Stack liegen, kann das schwere Folgen haben. Bei ungeschützten Betriebssystemen, wie DOS, kann daraus auch ein kompletter Absturz des Rechners werden, der nur noch durch die Hardwarereset-Taste oder durch Ausschalten zu beheben ist.
Die mem...()-Funktionen wurden vor allem beim Kopieren von Strukturen verwendet, die str...()-Funktionen für Texte. In ANSI-C können Strukturen auch durch die Zuweisung kopiert werden.
Da bisher die Suchfunktionen noch nicht besprochen wurden, verwendet das Programm einen kleinen Trick. Es unterstellt die DOS-Konvention, nach der die Kennung eines Dateinamens immer drei Zeichen lang ist, wenn es sich um eine ausführbare Datei handelt.
Die gewünschte Datei erhält man aus dem ersten übergebenen Argument, das den Programmdateinamen beinhaltet. Der Name wird mit Hilfe einer eingefügten Endekennunng verkürzt. Schließlich wird an den verkürzten Namen die Kennung ".txt" angehängt, so daß sich der neue Name ergibt.
#include <string.h>
char * strcat ( char * zielp, const char
* quellp);
char * strncat(char * zielp, const char *
quellp, size_t n);
Die verwendete Funktion heißt strcat() von Konkatenieren, der Addition von Texten. Diese Funktion gibt es wieder mit und ohne Längenbegrenzung. Im Gegensatz zu der Kopierfunktion sorgt strncat() immer für eine Endekennung.
Beim Zusammenhängen von Texten wird die erste Endekennung überschrieben und der neue Text angehängt, der seine eigene Endekennung mitbringt. Im Zielbereich muß daher der ursprüngliche Text sowie der hinzugefügte Text Platz haben. Eine Endekennung entfällt dabei.
Bild 5-13: Aufbau von Texten zur laufzeit (einfach)
Die Berechnung der Länge einer Dateikennung ist sicher ein Trick, der nur auf einem bestimmten Betriebssystem funktioniert. Solche Abhängigkeiten sind eher ein negatives Beispiel. Ein guter Programmierstil ist unabhängig von der Maschine. Das bisherige Beispiel soll daher noch einmal bei den Suchfunktionen besprochen werden.
Mit Hilfe einer Mischung aus strcpy() und strcat()-Aufrufen lassen sich beliebige Texte aufbauen. Eine ganz spezielle Anwendung für den Aufbau von Texten wäre der Aufbau eines Steuerstrings für die printf()-Funktion.
Vergleiche wollen aber auch herausfinden, ob eine Variable größer als die andere ist. Um eine Aussage über Größenverhältnisse zu machen, brauchen wir eine Meßlatte, die den Maßstab dazu angibt.
Im einfachsten Fall nimmt man einfach den verwendeten Code eines Buchstabens, betrachtet den Code als ganze Zahl und sagt dann, daß der mathematisch höherwertig codierte eben der größere sei. Die Meßlatte ist hier die physikalische Codierung eines Zeichens. Die Folge aber ist, daß bei einem Vergleich eines "ü" mit einem "z" das "ü" größer ist als das "z". Ob das immer so gewollt ist? (Die Bemerkung gilt für die Zeichensätze IBM 437 / 850 sowie ISO 8859-1.)
Der Vergleich mit Codes funktioniert recht gut, wenn man Englisch spricht und einen ASCII-Zeichensatz verwendet. Erheblich problematischer wird es, wenn man mit Akzenten, Umlauten oder sprachspezifischen Buchstaben zu tun hat. Neben den unterschiedlichen Zeichensätzen gibt es dann weitere mögliche Merkmale. Es ist noch lange nicht gesagt, daß ein Duden die gleiche Vorstellung hat, welcher Buchstabe vor dem anderen kommt, wie ein Telefonbuch.
Die meisten Vergleichsfunktionen der Bibliothek arbeiten mit der Auswertung des Zeichencodes und bestimmen damit, wer größer und kleiner sei. Im Zuge der Internationalisierung, der ein eigenes Kapitel gewidmet ist, wurden auch zusätzliche Funktionen eingeführt, die ortsübliche Besonderheiten berücksichtigen. Die Einführung in den Standard bedeutet noch lange nicht, daß dies auch schon in den meisten Compilern vorhanden ist. Sollten Sie Programme schreiben wollen, die "München" verstehen (und nicht nur "Muenchen"), dann versuchen Sie am besten, einen Compiler zu finden, der sich an die XPG3-Richtlinien (X/OPEN Portability Guide Version 3) hält.
#include <string.h>
int memcmp (const void *t1p, const void *t2p,
size_t n);
int strcmp (const char * t1p, const char
* t2p);
int strncmp( const char *t1p, const char
*t2p, size_t n);
int strcoll (const char * t1p, const char
*t2p);
size_t strxfrm (char *zielp, const char *quellp,
size_t n);
Die ersten drei Funktionen sind altbekannte Mitglieder der Standardbibliothek. Die beiden letzten wurden unter dem Einfluß internationaler Standardisierungsbemühungen vom ANSI-Kommittee neu aufgenommen.
Die Funktionen (außer strxfrm) vergleichen zwei Texte oder Bereiche aus char-Variablen und liefern ein Vergleichsergebnis zurück.
Ergebnis:
> 0: der erste Text ist größer
als der zweite
== 0: der erste Text ist gleich dem zweiten
< 0: der erste Text ist kleiner als der
zweite
Das Verhalten der Funktionen mem...() und str...() entspricht den Unterschieden bei den Zuweisungen. Bei den memcmp() Funktionen werden immer die angegebene Anzahl von Zeichen verglichen, bei den strcmp()-Funktionen ist die Anzahl nur die maximale Obergrenze. Der Vergleich endet schon vorher, wenn eine Textendekennung gefunden wird.
Die neuen Funktionen beschäftigen sich mit einer ortsüblichen Sortierreihenfolge. Diese Reihenfolge muß vorher mit der Funktion setlocale() (setze Schauplatz) gesetzt worden sein. Ein Schauplatz wird beschrieben durch die verwendete Sprache, eventuelle ortsgebundene Besonderheiten, den verwendeten Zeichensatz sowie eine mögliche Variante.
Die Unterstützung lokaler Besonderheiten ist relativ aufwendig. Der Vergleich wird daher langsamer sein als ein Codevergleich. Wie erwähnt, unterstützen außerdem die wenigsten Compilerhersteller heute die Funktionen korrekt. Trotzdem könnte es für jeden Programmierer eine sinnvolle Investition in die Zukunft seiner Programme sein, wenn er statt strcmp() strcoll() verwendet.
Solange man reine ASCII-Texte vergleicht, sind die Ergebnisse von strcoll() und strcmp() identisch.
Die letze Funktion, die im Rahmen der Vergleichsfunktionen besprochen werden soll, ist eine Transformationsfunktion, die im Rahmen von Vergleichen verwendet werden kann. Sie wird benutzt, um einen ortsabhängigen Text in einen Text zu wandeln, der im üblichen Zeichensatz der Maschine dargestellt ist.
Die Idee dabei ist, daß Vergleiche mit strcoll() recht aufwendig sind. Mit Hilfe einer einmaligen Transformation kann man den Text wandeln und danach mehrfach Vergleiche mit der normalen strcmp()-Funktion anwenden. In der Summe sollte man dabei dann Laufzeit sparen. Die Kombination aus den Funktionen strxfrm() und strcmp() liefert das gleiche Ergebnis wie ein Aufruf von strcoll().
Die Funktion strxfrm() liefert als Ergebnis die Anzahl der Zeichen, die im Ergebnis vorhanden sind. Es ist erlaubt, eine Pseudowandlung zu machen, um nur die notwendige Länge zu ermitteln. Dann übergibt man eine NULL als Zieltext. Das Ergebnis ist die Nettolänge, so daß ein Puffer um ein Zeichen größer angelegt werden muß.
Die näheren Einzelheiten und Beispiele finden Sie im Kapitel über örtliche Anpassungen.
#include <string.h>
void * memchr ( const void * tp1, int c,
size_t n);
char * strchr (const char * tp1, int c);
char * strrchr (const char * tp1, int c);
size_t strcspn (const char * tp1, const char
* tp2);
char * strprk ( const char * tp1, const char
* tp2);
size_t strspn ( const char * tp1, const char
* tp2);
char * strstr (const char * tp1, const char
* tp2);
char * strtok ( char * tp1, const char *
tp2);
Die Gruppe der Such- und Zerlegefunktionen ist die größte Untergruppe der Textbearbeitungsroutinen. Außer einer einzelnen mem...()-Funktion, die wieder einen angegebenen Bereich bearbeitet, kennen alle Funktionen den String-Begriff aus C.
Die Funktionen suchen entweder ein einzelnes Zeichen in einem String oder untersuchen einen Text mit Hilfe der Zeichen eines zweiten.
In der Ausgabe kann man den Index, also die Position, an der das Zeichen gefunden wurde, durch eine einfache Subtraktion von zwei gleichartigen Zeigern ermitteln. Das Ergebnis der Subtraktion gibt die Anzahl von typisierten Variablen an, die zwischen den beiden Zeigern Platz finden. Diese Berechnung ist nur sinnvoll, wenn die Suchfunktion nicht mit dem Rückgabewert NULL ein Mißlingen gemeldet hat.
Wie üblich wurde die Variable, die ein einzelnes Zeichen aufnimmt, als int definiert. Der Vergleich bezieht sich daher auf int. Vergleiche mit int könnten bei deutschen Zeichen zu Problemen führen (wegen der Vorzeichenerweiterung). Intern wird aber eine Konvertierung auf unsigned char vorgenommen, so daß auch Zeichen mit einem gesetzten höchsten Bit problemlos verglichen werden können.
Bild 5-14: Suche nach einem Zeichen in einem Bereich
Im memchr()-Beispiel wurde außerdem eine typische "if"-Abfrage verwendet. Die Bedingung bei "if" fragt ab, ob der Ausdruck sich zu int oder void * ergibt und als Ergebnis den numerischen Wert "0" hat. Daher kann auf einen explizit angegebenen Vergleich verzichtet werden.
Die Indexermittlung geschieht durch eine Subtraktion von Zeigern. Da eine Zeigersubtraktion die Anzahl der Elemente liefert, die zwichen die beiden Zeigerpositionen passen würden, erhalten wir eine ganze Zahl. Hier ist auch sichergestellt, daß der Zeiger, der von memchr() gefunden wird, größer oder gleich der Anfangsadresse des Feldes ist. Negative Ergebnisse sind daher bei der Subtraktion ausgeschlossen.
Die folgende Funktion strchr() arbeitet ganz ähnlich, wie memchr(), nur daß sie eben an einem Textende aufhört zu suchen. Hier sucht das Programm nach einem Zeichen, das der binären "0" entspricht. Die Endekennung des Textes wird hier als zugehörig zum Text angesehen und mit abgesucht. Mit dem Programm erhält man die Nettolänge des Textes ausgegeben.
Zur Längenermittlung gibt es allerdings noch eine eigene Funktion, sodaß dieser Spezialfall sonst nicht angewendet werden muß.
Bild 5-15: Suche nach der Endekennung eines Textes
Im Bild 15 wird der Suchwert mit einer Zahl "0" angegeben. Dies ist möglich, da die Zahl "0" die gleiche physikalische Darstellung hat, wie das Zeichen '\0'. In vielen Programmen findet man solche kleinen Unkorrektheiten, die sich durch die einfache Typkonvertierung von C einschleichen. Wie immer ist eine exakte Typisierung wünschenswert. Trotzdem sollte man als Programmierer sich mit dem verbreiteten Programmierstilen befassen, um auch Programme anderer Programmierer mehr oder weniger leicht lesen zu können.
Im Beispiel kommt noch eine Besonderheit bei der Ausgabe des Textes vor. Die Ausgabe möchte, daß ein "\" am Bildschirm erscheint. Da aber der "\" als Fluchtsymbol vom Compiler erkannt und normalerweise entfernt wird, sorgt ein zweites Fluchtsymbol für die Ausgabe von einem Zeichen.
Zur gerade besprochenen Funktion strchr() gibt es eine fast gleich arbeitende weitere Funktion strrchr(), die ebenfalls einen Text nach einem Zeichen absucht, allerdings beim Ende beginnt. Somit findet sie das letzte Auftreten eines Zeichens im durchsuchten Text. Mit dieser Funktion können wir den Umbau eines Dateinamens aus dem Bild 13 neu und besser schreiben.
Bild 5-16: Erweiterung des Namensaufbaues
Beim Aufbau eines neuen Dateinamens aus dem Namen eines ablauffähigen Programms sollte man möglichst allgemein vorgehen. Im Beispiel wird durch eine Abfrage berücksichtigt, daß es Betriebssysteme gibt, die ablauffähige Programme (Code und Scripten) in Dateien mit beliebigen Namen (ohne Kennung) ablegen können.
Der Sinn des obigen Beispiel könnte darin liegen, daß man zu jeder ablauffähigen Datei eine Hilfsdatei generiert, die die jeweils benötigten Texte enthält. Damit wäre eine leichte Anpassung an verschiedene Sprachen möglich.
Viele Programme, die für den internationalen Einsatz produziert werden, holen ihre Texte entweder aus solchen oder ähnlichen Dateien oder legen intern ein Feld an, das die notwendigen Texte enthält. Ziel ist, in einem Programm keine Texte hart zu codieren, um flexibel zu bleiben.
Die zweite Gruppe von Suchfunktionen nimmt einen Text und untersucht sein Verhältnis zu einem zweiten. Das erste Beispiel für diese Gruppe untersucht einen Text ab dem Anfang. Der Suchvorgang bricht ab, wenn ein Zeichen gefunden wird, das nicht in einem Referenztext enthalten ist.
Bei der Suche mit strspn() geht es um eine Mengenoperation, nicht um eine Teilstringsuche. Der zweite Referenztext liefert die Menge der möglichen Zeichen. Die Vergleichsfunktion bricht ab, wenn sie ein Zeichen findet, das in der Referenzmenge nicht enthalten ist.
Das Ergebnis gibt die Länge des Anfangstextes im ersten Text an, der ausschließlich aus den Referenzzeichen aufgebaut ist.
Von dieser Funktion gibt es auch eine logische Umkehrung. Mit strcspn() kann man einen Anfangstext suchen, dessen Zeichen nicht in der Referenzmenge enthalten sind. Wieder gibt der Rückgabewert die erkannte Länge an.
Bild 5-18: Suche nach Anfangstext (Ausschluß)
Solche Suchfunktionen sind u. a. für Compilerbauer sehr wichtig. Sie müssen eine Zeile einlesen und diese Zeile nach Namen, Operatoren und Leerzeichen absuchen. Ein Name endet, wenn ein Zeichen gefunden wird, das in einem Namen nicht vorkommen darf. Da innerhalb eines Namens die Operatorsymbole genauso verboten sind wie Leerzeichen, könnte man mit strspn() den entsprechenden Suchvorgang beschreiben.
Die Funktionen strspn() und strcspn() liefern Zähler zurück, mit denen man die gewünschte Position ermitteln kann. In den Fällen, in denen zur Weiterbearbeitung ein Zeiger auf das gefundene Zeichen benötigt wird, kann dieser Zeiger mit Hilfe einer kleinen Adreßrechnung gefunden werden. Dazu braucht man nur den Zähler auf den Startzeiger des untersuchten Textes addieren.
Es gibt nun eine weitere Funktion, die im Grunde das gleiche macht wie strspn(), aber einen Zeiger auf das gefundene Zeichen zurückliefert: strpbrk() (string pointer break).
Bild 5-19: Suche nach einem Anfangsstring mit Zeiger
Die erste der beiden Funktionen sucht in einem Text einen zweiten Text. Die Rückgabe zeigt auf den Beginn des gefundenen Teiltextes im ersten Text. Da der Beginn gemeldet wird, erhält man möglicherweise einen bedeutend längeren Text als Ergebnis. Allerdings beginnt dann der Ergebnistext immer mit dem gesuchten Text.
Im Fall, daß der gesuchte Text nicht gefunden werden kann, gibt strstr() wie üblich NULL zurück.
Mit Hilfe der strstr()-Funktion kann man z. B. in einem langen absoluten Dateinamen mit Pfadangabe den eigentlichen Dateinamen suchen.
Bild 5-20: Suche nach einem Teilstring
Es bleibt noch die letzte der Suchfunktionen. Die Funktion strtok() verhält sich ein wenig anders als die anderen Stringfunktionen. Mit ihr kann man einen Text mehrfach absuchen. Dazu speichert sie intern den Text in einem eigenen Puffer.
Mit strtok() kan man "tokens" finden. Ein "token" ist eine sinntragende Texteinheit. Token sind Schlüsselworte, Operatorsymbole oder eigene Namen des Anwenders. Eine wichtige Eigenschaft der Funktion ist es, daß man bei jedem neuen Suchauftrag innerhalb eines Textes jedesmal einen neuen Vergleichsstring angeben kann. Wenn also ein Compilerbauer eine Zeile des Quelltextes untersucht, dann kann er abhängig vom bereits erkannten Textelement die Suchstrategie jedesmal neu festlegen.
Im zugehörigen Beispiel holt sich das Programm aus der Umgebung den Inhalt der Variabalen PATH und gibt jeden einzelnen Suchpfad aus, der in PATH enthalten war. Die einzelnen Pfade, die nacheinander durchsucht werden sollen, werden innerhalb der Variablen durch ";" getrennt.
Bild 5-21: Zerlegen eines Textes in Texteinheiten
Die Zerlegefunktion strtok() sucht also nach dem jeweils nächsten Auftreten eines Kommas und liefert die zugehörige Adresse zurück. Beim ersten Aufruf gibt man den Text an, den man zerlegen möchte. Ein Teiltext wird als beendet betrachtet, wenn er durch ein oder mehrere Zeichen des zweiten Referenztextes abgeschlossen wird. In diesem Fall setzt strtok() unmittelbar hinter den gefundenen Teiltext eine Endekennung und liefert die Startadresse des Teiltextes zurück. Das heißt auch, daß der übergebene Text durch strtok() verändert wird.
Nachfolgende Aufrufe übergeben NULL als Textadresse. Dann wird der Suchvorgang im zuerst gesetzten Text fortgesetzt. Allerdings kann man bei jedem Suchvorgang einen neuen Referenztext angeben.
Bei der Ausgabe sieht man keine Strichpunkte, da sie beim Absuchen überschrieben wurden. Die Absuche wird beendet, wenn strtok() NULL zurückliefert und damit anzeigt, daß der Suchvorgang erfolglos war.
#include <string.h>
void * memset (void * bereich, int wert,
size_z laenge);
char * strerror (int errnummer);
size_t strlen (const char * ctext);
Die Funktion "strlen()" ermittelt während der Laufzeit die Nettolänge eines Textes, also ohne die Endekennung.
Bild 5-22: Verwendung von "strlen()"
Im ersten Beispiel zu strlen() wurde mit Hilfe von getenv() ein Zeiger auf die Umgebungsvariable PATH geholt mit strlen() ihre akutuelle Länge ermittelt. Nun könnte man mit dieser Rückgabe dynamisch Speicherplatz anfordern und die PATH-Variable kopieren.
Bild 5-23: Längenermittlung bei Texten
Das zweite Beispiel erstellt eine Struktur und definiert eine zugehörige Initialisierungsfunktion. Da innerhalb der Initialisierungsfunktion die aktuelle Länge des übergebenen Textes nicht bekannt sein kann, muß die Länge zur Laufzeit ermittelt werden, was mit strlen() möglich ist. Die Arbeitsweise von strlen() entspricht der Suche nach der Endekennung mit strchr(), die auf den vorangegangenen Seiten schon besprochen wurde.
Eine wichtige Aufgabe eines Programms ist es, eventuelle Fehler so genau wie möglich zu beschreiben. Bei Fehlern, die beim Aufruf der Betriebssystemschnittstelle erkannt werden, gibt es die globale Variable errno, die dann eine Fehlernummer beinhaltet. Um von dieser Fehlernummer auf einen aussagekräftigen Text zu kommen, gibt es die Funktion perror(), die diese Umschlüsselung macht. Innerhalb der Funktion perror() wird die eigentliche Umsetzfunktion strerror() gerufen.
Je nach Implementierung greift strerror() auf eine allgemeine Datei zu oder aber auf eine Adreßtabelle, in der alle möglichen Fehlertexte hinterlegt sind.
Eine korrekte Fehlermeldung dient als wichtige Hilfestellung für den Benutzer. Vorausgesetzt wird allerdings oft, daß der ahnungslose Benutzer eines fertigen Programmpaketes englisch spricht.
Sehen wir uns daher zwei Beispiele an. Das erste Beispiel verwendet die globale Fehlervariable, um von strerror() den passenden Fehlertext zu erhalten. Der Text wird im Normalfall in englischer Sprache formuliert sein, sofern nicht schon länderspezifische Varianten vorgesehen sind.
Bild 5-24: Normale Verwendung von "strerror()"
Das zweite Beispiel gibt mit Hilfe einer Schleife alle bekannten Fehlermeldungen aus. Dabei setzen wir voraus, daß strerror() ungültige Fehlernummern abfängt. Die zurückgelieferten Texte beinhalten eine Zeilenschaltung am Ende, so daß jede Fehlermeldung automatisch in einer eigenen Zeile erscheint. Als Höchstgrenze für Fehlernummern wird hier "50" angenommen.
Im ANSI-Standard wird kein Makro festgelegt, daß uns diese Anzahl der gültigen Fehlermeldungen angibt. Dies dürfte ein Versäumnis sein.
Bild 5-25: Ausgabe der bekannten Fehlermeldungen
Wenn man die Ausgabe des zweiten Beispiels in eine Datei umleitet, den Inhalt übersetzt und eine eigene strerror()-Funktion schreibt, dann hätte man für einen Benutzer, der vor einem fertigen Anwendungspaket sitzt, auch die Systemfehlermeldungen eingedeutscht. Voraussetzung ist nur, daß die eigene Funktion vor der allgemeinen Systembibliothek eingebunden wird.
Wenden wir uns zuletzt der Initialisierung zu. Die Initialisierung wird selten verwendet. Fordert ein Programm wie im Beispiel auf der folgenden Seite dynamischen Speicherplatz an, dann wird zumeist der Speicherbereich durch die Verwendung vorbelegt. Ein strcpy() belegt in einem angeforderten Puffer nur die notwendige Zeichenzahl vor; eine Vorlegung des ganzen Puffers würde auch unbenutzte Zeichen mit vorbelegen.
Bild 5-26: Initialisierung eines dynamischen Puffers
Der Name "Resource" wird für sehr viele und völlig unterschiedliche Anwendungen verwendet. Hier steht er für eine Datei, die für ein bestimmtes Programm Festlegungen trifft.
Das erste Beispiel ruft eine Funktion strerror() auf. Diese Funktion haben wir bereits als ANSI-C-Funktion besprochen. In diesem Fall wollen wir annehmen, daß die Funktion selbst geschrieben wurde und ihre Fehlermeldungen aus einer Datei liest. Da die Datei mit jedem Texteditor verändert werden kann, ist eine Anpassung an ortsübliche Sprachgewohnheiten leicht möglich.
Der Testrahmen ruft einfach mehrmals die Fehlertextfunktion auf und gibt den Rückgabetext aus. Die Funktion muß dabei negative und zu große Fehlernummern abfangen.
Bild 5-27: Testrahmen für deutsche Systemmeldungen
Die Implementierung der Ersatzfunktion für stderr() prüft zuerst, ob die übergebene Fehlernummer negativ ist. In diesem Fall liefert sie den Standardtext "Unbekannte Fehlernummer" zurück. Der Text enthält am Ende eine Zeilenschaltung.
Der nächste Test prüft, ob die verwendete Fehlermeldungsdatei bereits geöffnet wurde. Falls nicht, beginnt die Funktion mit dem Aufbau eines Dateinamens. In den Richtlinien von X/OPEN ist festgelegt, daß es neben den Einstellungen von ANSI-C eine Umgebungsvariable LC_MESSAGES geben soll, die den Pfad für den sogenannten Meldungskatalog enthält.
Die hier gewählte Form ist nicht vollständig kompatibel zu X/OPEN, zeigt aber trotzdem das generelle Vorgehen. An den über die Umgebungsvariable erhaltenen Pfad hängt die Funktion "/msg.txt" an und bildet damit den Dateinamen. Der Dateizeiger wird in einer lokalen static-Variablen gehalten, so daß der Inhalt der Variablen zwischen Aufrufen erhalten bleibt.
In einer Schleife wird nun Zeile für Zeile die angegebene Datei gelesen, bis die gewünschte Zeile gefunden wurde. Im Fehlerfall, was bei zu großen Fehlernummern möglich ist, gibt die Funktion wieder den Standardtext zurück.
Das Schließen der Datei überlassen wir der Umgebung am Ende des Programmes.
Der Zeitbedarf ist gegenüber einem Zugriff auf ein Adreßfeld wesentlich höher. Aber was macht das? Schließlich sollten Systemfehlermeldungen nicht allzuoft auftauchen.
Bild 5-28: Ausgeben eigener Texte mit "strerror()"
Umgekehrt gilt das gleiche. Die Zahlen, die in einem Programm berechnet werden und am Bildschirm angezeigt werden sollen, müssen zuerst aus ihrem jeweiligen Zahlenformat zu einem Text gewandelt werden, damit der Bildschirm sie anzeigen kann.
#include <stdio.h>
int fprintf ( FILE * fp, const char * format,
...);
int fscanf ( FILE * fp, const char * format,
...);
int printf ( const char * format, ...);
int scanf ( const char * format, ...);
int sscanf ( const char * quelle, const char
* format, ...);
int sprintf ( char * ziel, const char * format,
...);
int vsprintf(char *ziel,const char * format,va_list
arg);
int vfprintf(FILE *fp,const char * format,va_list
arg);
int vprintf ( const char * format,va_list
arg);
Zur Wandlung kennt ANSI-C eine ganze Anzahll von Funktionen. Die bekanntesten sind vermutlich printf() und scanf(). Die Deklarationen dazu befinden sich in der Informationsdatei stdio.h.
Die beiden Funktionen gibt es mit unterschiedlichen Parameterlisten. Der allgemeine Fall gibt als ersten Parameter eine Verbindung zu einer Datei an. Hier liest oder schreibt man aus bzw. in eine Datei. Ein Sonderfall ergibt sich, wenn man die Dateiangabe wegläßt und die Standardverbindungen benutzt.
Ein spezieller Fall ist das Lesen und Schreiben in den Speicher. Ein Feld aus char dient dann als Ziel oder Quelle der E/A-Operationen.
Den dritten Fall gibt es nur für die Ausgaben. Der Parameter, der die Ausgabeinformation angibt, ist eine Parameterliste des Typs va_list. Diese Funktionen können daher nur innerhalb einer anderen Funktion aufgerufen werden, die ebenfalls eine variable Schnittstelle besitzen. Nur Funktionen mit variabler Schnittstelle legen mit Hilfe der va_... Makros aus der Informationsdatei stdarg.h eine Liste der eigenen Parameter an und können dann diese Liste auch an andere Funktionen, wie hier die vprintf()-Funktionen, weitergeben.
Weitere Beispiele für eine variable Parameteranzahl werden im Kapitel "Von K&R zu ANSI" diskutiert.
#include <stdlib.h>
int atoi(const char * cp);
long atol(const char * cp);
long strtol (const char *start, char **ende,
int basis);
unsigned long strtoul(const char *s,char
**e, int basis);
double strtod (const char *start, char **ende,
int basis);
Die erste Funktion, atoi(), heißt ausgesprochen "ascii to integer", wobei mit "ascii" eben ein Text gemeint ist, dessen Zeichen sich im ASCII-Code darstellen lassen. Auch wenn der ANSI-Standard ausdrücklich festlegt, daß der Zeichensatz der Sprache nicht ASCII sein soll, so sind doch die historischen Einflüsse immer wieder zu bemerken.
Bild 5-29: Arbeiten mit "atoi()"
atoi() liest einen Text, der aus führenden Leerzeichen (white space), einem mögliche Vorzeichen und einer Ziffernfolge bestehen kann und wandelt diesen Text dann in eine int-Zahl. Die Ziffernfolge muß eine dezimale Zahl darstellen.
Das Verhalten im Fehlerfall ist abhängig vom verwendeten Compiler. Zumeist wird "0" zurückgegeben, wenn die Wandlung nicht möglich ist. Ein Überlauf wird nicht erkannt. Im Beispiel wird der Überlauf durch einen 10-stelligen Text erzeugt.
Die zu wandelnde Zahl muß am Anfang des Textes stehen, da der erste Buchstabe, der keine Ziffer ist, die Wandlung abbricht.
Eine sehr ähnliche Funktion heißt atol() und liefert einen long-Wert zurück.
Bild 5-30: Arbeiten mit "atol()"
Beim Aufruf der printf()-Funktion müssen wir nun im Bild 30 beim Formatelement long berücksichtigen. Im Gegensatz zum atoi()-Beispiel liefert atol() einen korrekten Wert beim letzten, 10-stelligen Text. Ansonsten gelten die gleichen Randbedingungen für beide Funktionen.
Bild 5-31: ANSI-Wandlung nach long
Am Beispiel von strtol() im Bild 31 können wir die Möglichkeuiten erkunden. Die Funktion strtol() erwartet drei Parameter und liefert einen vorzeichenbehafteten long-Wert als Ergebnis. Der erste Parameter ist ein Zeiger auf den Beginn des Textes, der gewandelt werden soll. Im einfachsten Fall genügt diese Angabe bereits. Die beiden anderen Parameter können NULL bzw. "0" sein.
Der Rückgabewert ist die gewandelte Darstellung der Zahl, die am Anfang des Textes steht. Im Gegensatz zu atol() kann die Zahl aber nun auch in der üblichen Darstellung für dezimale, oktale oder hexadezimale Zahlen angegeben sein. Die dezimalen Zahlen haben dabei keine führende "0", oktale Zahlen beginnen mit einer führenden "0" und hexadezimale Zahlen beginnen mit "0x" oder "0X".
Der zweite Parameter kann zur Rückgabe des Endes der erkannten Zahl verwendet werden. Dies ist besonders dann nützlich, wenn in einem Text mehrere Zahlen eingestreut sind, die nacheinander gelesen werden sollen. Dazu wird an strtol() die Adresse einer Zeigervariablen übergeben, der der Beginn des Textrestes nach der Zahl übergeben werden kann.
Der dritte Parameter gibt die gewünschte Konvertierungsbasis an. Zumeist wird man hier "8" für oktal, "10" für dezimal oder "16" für hexadizimal finden. Es sind aber Zahlenbasen zwischen 2 und 36 erlaubt. Dabei wird unterstellt, daß Ziffern gößer 10 als Buchstabe ab "a" dargestellt werden, wie es bei hexadezimalen Zahlen üblich ist. Zwischen Groß- und Kleinbuchstaben wird dabei nicht unterschieden.
Ist die gewählte Zahlenbasis größer als 16, dann werden auch die nach "f" folgenden Buchstaben gültige Ziffern. Aber das dürfte wohl selten verwendet werden.
Die ANSI-Wandlungsfunktionen sind erheblich leistungsfähiger als die ato..()-Funktionen, ohne erheblich mehr Laufzeit zu kosten. Neue Programme sollten daher nach Möglichkeit die neuen Funktionen benutzen.
Ein weitere Eigenschaft der neuen Funktionen ist es, daß sie der mögliche Anpassung an ortsübliche Gegebenheiten und Schreibweisen unterliegen, soweit dies in dem verwendeten Compiler realisiert wurde. Die Anpassung an den "Schauplatz" (locale) des Programmes ist per Programm einstellbar. Näheres finden Sie im Kapitel "Örtliche Anpassung".
Ein wünschenswertes Beispiel für eine Anpassung an ortsübliche Gewohnheiten ist die Darstellung von Geldbeträgen. Im Deutschen trennt man die Pfennige mit einem Komma ab, in den USA werden die Cents durch einen Punkt abgeteilt.
Beträge, die Bruchteile umfassen stellt man am besten mit double dar. Es gibt daher eine Wandlungsfunktion von Text auf double. Sie arbeitet ähnlich der gerade besprochenen strtol()-Funktion, aber akzeptiert nur dezimale Zahlen. Die Darstellung der Fließkommazahl kann jedoch mit einem Dezimalpunkt oder mit Exponentialdarstellung oder beidem erfolgen. Natürlich sind die üblichen Vorzeichen für Mantisse und Exponent gestattet.
Bild 5-32: Wandlung von Geldbeträgen
Im Beispiel wollen wir einen Geldbetrag in einer ortsüblichen Darstellung einlesen. Die Funktion strtod() liest einen Text und interpretiert den Anfang des Textes als double-Zahl. Das Ergebnis und der Zeiger auf das Zeichen nach der Zahl wird zurückgeliefert.
Der erste Text entspricht der US-amerikanischen Schreibweise und wird daher korrekt eingelesen. Der zweite Text enthält ein Komma. Die Konvertierung wird daher abbrechen und die Pfennige nicht berücksichtigen. Will man das umgekehrte Verhalten erreichen, kann man mit Hilfe der Funktion setlocale() die Einstellungen für das Dezimalpunktzeichen ändern und damit das Verhalten des Programmes umkehren. Diese Möglichkeit besteht heute leider nur in wenigen Compilern, sodaß es immer noch als Spezialität anzusehen ist. Wie schon erwähnt, finden Sie eine ausführliche Diskussion im Kapitel über örtliche Anpassungen.
Die letzte der drei ANSI-Konvertierungsfunktionen ist nur eine Variation der strtol()-Funktion. Sie heißt strtoul() und liefert einen unsigned long-Wert. Ansonsten entspricht sie vollkommen der long-Konvertierungsfunktion.
Beispiele sind die Benutzereingaben. In sehr alten Programmen hat man vom Benutzer die Eingabe eines Kommandos oder einer anderen Eingabe erwartet und nach der Eingabe der ganzen Zeile überprüft, ob die Eingaben des Benutzers korrekt sein können. Im Fehlerfalle mußte er die ganze Zeile noch einmal eingeben oder vielleicht konnte er die ganze Zeile dann editieren.
Sicher ist es bedeutend benutzerfreundlicher (user friendly), eine Eingabe des Benutzers bei jedem Tastendruck zu prüfen und auf fehlerhafte Eingaben entweder gar nicht zu reagieren oder aber eine Warnung auszugeben. Nebenbei bemerkt, ist der Begriff Benutzerfreundlichkeit in seiner wörtlichen Übersetzung einer der wenigen von Europa aus geprägten Begriffe in der EDV.
Dazu benötigen wir zwei Voraussetzungen: zum einen müssen wir jedes einzelne Zeichen prüfen können und zum anderen muß die Eingabe zeichenweise stattfinden. Sie darf nicht gepuffert werden.
Zum Prüfen der einzelnen Zeichen stehen eine ganze Anzahl von Makros (oder Funktionen) zur Verfügung, die in der Informationsdatei ctype.h deklariert werden. Im Fall der Makros werden diese natürlich definiert.
Die ungepufferte Eingabe ist abhängig vom Betriebssystem. DOS kennt eine Funktion getch(), die von der Tastatur zeichenweise liest. Der Name ist aus dem curses-Paket von UNIX entliehen (curses ist ein Paket für die Bildschirmsteuerung). In anderen Betriebssystemen wird man einfach dem Treiber mitteilen, daß er die Pufferung unterlassen soll. Dies geschieht heute unter UNIX mit ioctl()-Aufrufen oder früher mit stty()-Aufrufen.
Bild 5-33: Vereinfachte Eingabe einer Fließkommazahl
Sehen wir uns als Beispiel eine einfache Zahleneingabe an. Alle Ziffern und ein Punktzeichen sei erlaubt. Das Programm steht im Bild 33. Als Eingaben werden alle dezimalen Ziffern sowie die Punktierungszeichen akzeptiert. Für den Fall, daß ein Punktierungszeichen erkannt wird, wird die weitere Eingabe von Punktierungszeichen gesperrt.
Bild 5-34: Test der Zeichen mit Stringfunktion
Ein lokales Problem ist es, welches Zeichen die Trennung zwischen der Zahl und ihren Nachkommastellen bewirken soll. Mit Hilfe einer XPG3-Umgebung ist dies einstellbar. Sehen Sie dazu auch das Kapitel über örtliche Einstellungen.
Bild 5-35: Statistische Auswertung einer Textdatei
Da im Beispiel keine Rücksicht auf den verwendeten Trenner genommen wird, erhält man, die US-amerikanische Version vorausgesetzt, den richtigen Wert angezeigt, wenn man einen Punkt verwendet hat und nur die ganze Zahl, wenn man ein Komma als Trenner benutzt hat.
Die eingegebenen Zeichen werden in einem Puffer gesammelt. Auf eine Prüfung auf Überlauf des Puffers wurde verzichtet. Die eingegebene Zeichenkette wird dann in eine Fließkommazahl gewandelt. Ein reine ASCII-Wandlung wäre mit atof() möglich.
Eine andere Lösung könnte eine der Zeichenmengenfunktionen des Standards benutzen. Allerdings gerät man auch dann in die Probleme der nationalen Anpassung.
Bild 5-36: Die Funktion zur Zeichenklassifizierung
Das Beispiel im Bild 34 kodiert "hart" ein Komma als Trenner zwischen der Zahl und den Nachkommastellen. Da aber "strtof()" unter dem verwendeten Compiler nur den US-Punkt als Trenner kennt, erhält man einen falschen Wandlungswert. Solche Programm sind sicher keine Programme, wie man sie in einem Produkt erwartet. Sie sollen aber Hinweise auf mögliche Problemfelder geben.
Die vollständige Auswertung von Zeichen kann man sehen, wenn ein Programm ein Datei einliest und eine Statistik über die möglichen Zeichenklassen erstellt (Bild 35 und 36).
Im Beispiel werden alle Klassifizierungsfunktionen des Standards verwendet und zusätzlich noch isascii(). Die letztere Funktion ist nicht bei ANSI definiert, aber auf den meisten DOS und UNIX-Maschinen anzutreffen.
Die Implementierung der Makros wird zumeist mit Hilfe einer Tabelle gemacht. Die benutzte Tabelle ist 257 Bytes groß. Damit haben alle möglichen 256 Zeichen einer char-Variablen Platz und zusätzlich EOF. Nebenbei bemerkt, wurde die minimale Fallanzahl in einer switch()-Anweisung, die ein Compiler bearbeiten können muß, wegen dieser Tabelle auf 257 gesetzt.
Ein Eintrag in der Klassifizierungstabelle besteht aus einem Bitmuster, das die Klassen eines Zeichens beschreibt. Will man ein Zeichen klassifizieren, dann verwenden die Makros das Zeichen als Index in die Tabelle, holen das Bitmuster heraus und testen das Bit, das für die zu überprüfende Bedingung zuständig ist.
Beim Zugriff wird auf den Zeichencode meist eins addiert, um EOF zu berücksichtigen, das im ersten Eintrag beschrieben wird.
Mit dieser Tabelle könnte man im Prinzip sehr einfach und sehr schnell die gewünschten Bewertungen durchführen. In der Praxis ergeben sich aber wieder einmal Schwierigkeiten. Es gibt recht schlampige Implementierungen, die von einem ASCII-Zeichensatz ausgehen und statt eines sauberen Tabellenzugriffs eigene Berechnungen anstellen.
Diese Compiler sind, auch wenn sie sonst ANSI-kompatibel sind, in diesem Punkt problematisch.
Ein anderes Problemfeld sin Wandlungen von Groß- auf Kleinbuchstaben und umgekehrt. Im Standard werden dazu zwei Funktionen definiert tolower() und toupper().
Im Prinzip müßten diese beide Funktionen wieder mit Hilfe von zwei simplen Tabellen realisiert werden. Die eine Tabelle enthält dann die Großbuchstaben und die zweite die Kleinbuchstaben. Verwendet man wieder ein Zeichen als Index, kann man schnell zu einem gegebenen Zeichen das gewünschte Gegenstück finden.
Bild 5-37: Wandlung auf Groß- und Kleinbuchstaben
Wieder sind hier viele Compilerbauer nicht ANSI-konform. Der Übergang von einer Zeichenart zu anderen wird häufig berechnet oder es wird ein Bit gesetzt oder rückgesetzt. Dies ist bei einem reinen 7-Bit-ASCII-Zeichensatz leicht möglich, da sich Groß- und Kleinbuchstaben um den Betrag "0x20" oder um ein gesetztes oder rückgesetztes Bit 2 hoch 5 unterscheiden.
Bereits bei den Zeichensätzen der PCs stimmt dies aber nicht mehr für die zusätzlichen Zeichen oberhalb 127. Vielleicht geht hier das Speichersparen doch zu weit.
In der Praxis werden solche Zeichenwandlungen benutzt, um Abfragen zu vereinfachen. Bevor eine Eingabe geprüft wird, kann man durch eine Wandlung sicherstellen, daß man nur eine Abfrage schreiben muß. Die Wandlung liefert kann auch dann aufgerufen werden, wenn das Zeichen bereits im richtigen Format vorliegt, oder wenn es kein Gegenstück im Codesatz gibt. In diesem Fall wird einfach das übergebene Zeichen zurückgeliefert.
Vielleicht ist das auch ein Grund für die größere Akzeptanz in den USA, die solche Anpassungsprobleme nicht haben. Mit dem Erscheinen der PCs und mit der zunehmenden Verwendunug internationaler Zeichensätze ist es zumindest möglich, die nationalen Besonderheiten im Rechner darzustellen.
Was oft noch fehlt, ist die Anpassung der Bibliotheken und Makros. Wie schon erwähnt, ist diesen Problemen ein eigenes Kapitel gewidmet ("Örtliche Anpassung").
![]()