In wirklichen Produkten treten weit größere Probleme auf. Dort werden Texte oft aus einer Textdatei gelesen, um verschiedene Sprachen zu unterstützen. Dort finden wir auch Probleme, die man als Programmierer während der Programmerstellung gar nicht genau vorhersagen kann.
Dann beginnt der Bereich der dynamischen Programmierung. Wir können dabei sowohl Daten als auch Funktionen einbeziehen. Ein Beispiel für einen unbekannten Bedarf an Variablen bietet jeder Editor. Woher soll man beim Programmieren eines Editors wissen, wie groß die Texte sein werden, die der Benutzer erstellt wird? Daher muß der Programmierer besondere Verfahren benutzen, um mit wechselden Platzanforderungen fertig zu werden.
Einen anderen Fall finden wir bei einem Terminalprogramm, das den eigenen Rechner über eine serielle Verbindung mit einem anderen verbindet. Über die Schnittstelle kommen sowohl Daten als auch Steuerzeichen. Falls die Verbindung über eine Modemstrecke läuft, können auch völlig zufällige Daten durch gestörte Übertragungsleitungen entstehen. Es ist nun Aufgabe des Programms, die Nutzdaten so gut wie möglich herauszufinden.
Ein drittes Beispiel liefern die graphischen Oberflächen mit ihren vielen Eingabe- und Steuermöglichkeiten. Hier werden an die dahinterliegenden Programme erhebliche Anforderungen an die Bedienung der Benutzereingaben gestellt. Die Reihenfolge der Eingaben ist durch den Programmierer dabei nicht mehr vorhersehbar.
Formale Parameter werden als Teil des Funktionsaufrufes dynamisch angelegt und mit den Werten der zugehörigen aktuellen Parameter initialisiert. Ebenfalls ein Teil der Aufrufsequenz einer Funktion ist das Anlagen des Speicherbereiches, der für die lokalen Variablen der Funktion benötigt wird.
Bild 4-1: Übergabe von Parametern und lokale Variable
Technisch werden in "C" die formalen Parameter vor einem Aufruf jedesmal neu am Stack angelegt. Dies gilt auch für die lokalen Variablen. Am Ende des Unterprogramms werden die lokalen Variablen und die formalen Parameter zusammen mit der üblichen Rückkehradresse wieder vom Stack entfernt.
Der Funktionsblock bestimmt damit den Gültigkeitsbereich von formalen Parametern und lokalen Variablen. Rückgaben können daher nicht über den Stack erfolgen, da sie ja erst nach dem Verlassen der Funktion im Gültigkeitsbereich der aufrufenden Funktion benötigt werden. Hier muß der Rückgabewert also über die Grenze eines Gültigkeitsbereiches erhalten werden. Der Rückgabewert wird (zumeist) in ein Register geschrieben und kann danach vom aufrufenden Programm abgeholt werden.
Der zur Verfügung gestellte Speicherplatz gehört nicht dem Programm. Er gehört immer noch dem Betriebssystem. Im Programm steht uns nur ein Zeiger auf den dynamisch reservierten Bereich zur Verfügung.
#include <stdlib.h>
void * malloc ( size_t size);
void * calloc (size num, size_t size);
void free (void * ptr);
Die einfachste Funktion ist malloc(). Man übergibt ihr die Anzahl der benötigten "Grundeinheiten". Die Grundeinheit der Speicherverwaltung ist die Größe einer char-Variablen. In unserem Sprachraum kann man dies auch mit einem Byte gleichsetzen. In fernöstlichen Ländern gibt es auch Multibyte-Zeichensätze. Auch in den westlichen Ländern wird zunehmend der Gebrauch des Unicodes üblich (Windows NT, Java).
Der Datentyp size_t ist der Datentyp, der von sizeof zurückgeliefert wird. Vielleicht sehen Sie einmal in der stdlib.h nach, wie bei Ihrem Compiler der Typ definiert wurde. Häufig wird size_t mit unsigned int definiert.
Der zurückgelieferte Zeiger hat keinen Typ. Er muß vom Programmierer explizit mit einer Typwandlung versehen werden.
Bild 4-2: Anlegen und Freigeben von Speicherplatz
Der Programmierer erhält also einen typlosen Speicherbereich, den er selbst verwaltet und für dessen korrekte Benutzung er selbst verantwortlich ist. Dies gilt insbesondere für die Grenzen. Selbst Betriebssysteme, die über Speicherschutz verfügen, werden im allgemeinen darauf verzichten, alle mit malloc() angelegten Bereiche in den Schutzmechanismus einzubeziehen. Der Aufwand wäre erheblich. Der Inhalt des reservierten Bereiches ist zufällig. Er wird von der Speicherverwaltung nicht initialisiert.
malloc() liefert im Fehlerfall den Wert NULL als Kennung zurück und zeigt damit an, daß kein Speicherplatz mehr angelegt werden konnte. Die Variable errno wird nicht gesetzt, so daß keine weitergehende Fehleranalyse möglich ist.
Mit Hilfe des Zeigers findet die Speicherverwaltung nicht nur den reservierten Datenbereich, sondern auch die Verwaltungsinformationen dazu. Daher darf der zurückgegebene Zeiger in keinerlei Weise vom Programmierer verändert werden. Am besten legt man ihn in eine Variable, die nur in Zuweisungen gelesen wird. Dies wurde im Beispiel eingehalten. Um in den for-Schleifen einen Zeiger verändern zu können, wurde eine Hilfsvariable definiert.
In jedem Fall muß ein angeforderter Speicherplatz wieder zurückgegeben werden. Der Funktionsaufruf zur Rückgabe ist free(). Der an free() übergebene Zeiger muß von einem malloc()-Aufruf stammen und darf, wie schon erwähnt, in keiner Weise verändert worden sein.
Bild 4-3: Anlegen eines initialisierten Feldes
Neben malloc() gibt es eine weitere Funktion, die ein initialisiertes Feld anlegen kann: calloc(). Diese Funktion ruft man mit der Angabe der Elemente und deren Größe auf. Der reservierte Bereich wird mit einem Bitmuster initialisiert, das nur aus Nullen besteht. In vielen Fällen entspricht diese Vorbesetzung sowohl einer ganzen Zahl "0" als auch der ungültigen Adresse NULL. Da dies aber nicht Teil des Standards ist, sollte man sich besser nicht auf eine wie immer geartete Vorbesetzung verlassen.
Im Beispiel wird ein Feld aus 100 int-Elementen angelegt. Ein Teil davon wird in einer Schleife vorbesetzt (von 10 bis 99). Danach werden alle Werte ausgegeben. Die ersten 10 Ausgabezeilen sollten nun mit "0" erscheinen.
Natürlich benötigt calloc() für seine Aufgabe mehr Zeit als ein vergleichbarer malloc()-Aufruf. Als Programmierer wird man überlegen, ob es einen Sinn ergibt, wenn man einen initialisierten Speicherbereich anfordert, den man sowieso wieder überschreibt.
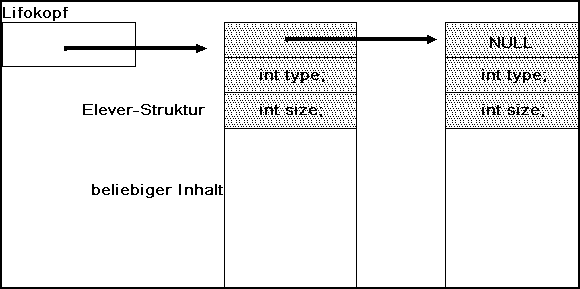
Bild 4-4: Aufbau einer FIFO-Liste
Jede Liste enthält einem Kopf, der die Liste verwaltet. Im Kopf gibt es je nach Implementierung unterschiedliche Daten. Immer sind ein oder mehrere Zeiger auf das erste Element der Liste (oder Kette) und möglicherweise auch auf das letzte Element vorhanden. Daneben sind weitere Informationen denkbar. Ein Zähler könnte die Anzahl der Elemente angeben, die mit diesem Anker verwaltet werden. In der Informationsdatei lifo.h wurde die Kopfstruktur lifokopf mit einem einzigen Zeiger aufgebaut.
Bild 4-5: Informationsdatei zur LIFO-Liste
Die Zeiger im Listenkopf (Anker) zeigen auf Elemente der Liste. Im einfachsten Fall der Lifo-Liste, die wir als erstes besprechen wollen, gibt es nur einen Zeiger auf das erste Element. Die danach folgende Fifo-Liste benötigt zwei Zeiger. Einer zeigt auf das erste Element, und der zweite verweist auf das letzte.
Was ist nun unter dem Listenelement zu verstehen? Ein Element ist eine strukturierte Variable mit einem bestimmten Aufbau. Jedes Element setzt sich aus Verwaltungsdaten und Nutzdaten zusammen. Für die Liste ist nur der Aufbau der Verwaltungsdaten wichtig. Der Aufbau der Nutzdaten ist unerheblich. Im Bild heißt die Verwaltungsstruktur elever für Elementverwaltung. Ein Zeiger ep zeigt in einem Element auf das jeweils nächste. Zwei mögliche Erweiterungen für eine allgemeinere Verwaltung wurden als Kommentare angedeutet.
Im Anker definieren wir daher den oder die Zeiger als Zeiger auf die Verwaltungsinformation, die jedes Element am Anfang enthalten muß. Ein leerer Anker wird mit NULL vorbesetzt.
![[einfache Liste]](Liste.gif)
Bild 4-6: Lifo-Liste: Einhängen eines Elementes am Kopf
Ein neues Element wird nun durch eigene Operatorfunktionen der Kopfstruktur eingehängt (oder eingekettet) und wieder entfernt (ausgehängt oder ausgekettet). Wichtig bei diesen Operationen ist es, daß sie ausschließlich mit Zeigern arbeiten. Die eigentlichen Daten bleiben unberührt an ihrem alten Platz. Dadurch sind diese Grundoperationen sehr schnell und unabhängig von der momentanen Größe der Liste.
Das Ende der Liste wird durch den Wert NULL im ep-Zeiger des letzten Elements gekennzeichnet. Eventuell gibt es eine Information über das letzte Element im Kopf der Liste, wie wir bei der Fifo-Liste sehen werden.
Bild 4-7: Ein- und Aushängen von Listenelementen
Der Listenkopf lifokopf besteht aus einem Zeiger auf die Elementverwaltungsstruktur. Ein Element, das in die Liste (oder Kette) eingehängt wird (Ltext), besteht seinerseits aus einem Verwaltungskopf (Elever) und den Nutzdaten (char text[]). Die Strukturen wurden in der Informationsdatei lifo.h beschrieben.
Bild 4-8: Ein- und Ausketten mit der Lifo-Liste
Will man in eine solchen Liste ein neues Element aufnehmen, dann kann dies nur am Kopf erfolgen. Nur dort beginnt eine Verweiskette von Element zu Element. Und nur am Anfang kann man ein Element auch wieder entfernen.
Die Operatorfunktionen machen sehr starken Gebrauch von Zeigern. Die Funktion Lifoein() erwartet einen Zeiger auf den zu benutzenden Listenkopf sowie einen Zeiger auf das einzukettende Element. Da die Elemente sehr verschieden sein können, wurde ein allgemeiner Zeiger auf void verwendet. In unserer Listenverwaltung kümmern wir uns nicht um den Inhalt oder den Aufbau eines Elements, solange es nur am Anfang die notwendige Verwaltungsinformation bereitstellt.
In der Implementierung wird der allgemeine Zeiger explizit mit einer Typkonvertierung (cast) zu einem Zeiger auf die Verwaltungsinformation des Elements gewandelt. Mit dem konvertierten Zeiger wird auf den Zeiger im Verwaltungsteil des neuen Elements zugegriffen und die Adresse eingetragen, die bisher im Kopf stand. Die Adresse des neuen Elementes wird dann nach entsprechender Typkonvertierung im Kopf abgelegt. Damit haben wir das neue Element am Listenkopf eingehängt.
Beim Aushängen liefert die Funktion Lifoaus() einen Zeiger auf das ausgekette Element zurück oder NULL, falls die Liste leer war. Im Kopf wird nun der Zeiger eingetragen, der im ausgeketteten ersten Element auf das folgende zweite zeigte.
ANSI-C hat durch seine Typprüfung die C-Programme erheblich sicherer gemacht. Für den Programmierer von allgemein verwendbaren Funktionen, wie den Listenoperationen, ergibt sich daher nun die Notwendigkeit, die Typwandlungen sehr genau anzugeben. In älteren "C"-Programmen hat man einfach unterstellt, daß der Verweiszeiger ganz am Anfang eines jeden Elements liegen mußte und den Elementzeiger direkt zum Zugriff benutzt. Die ANSI-Version mit Typprüfung durch den Compiler ist vorzuziehen.
Bild 4-9: Ausgabe der Lifo-Demonstartion
Die Lifo-Liste kann man an Hand eines einfachen Beispiels (listlifo.c) demonstrieren. Im Programm werden drei Texte in Variablen mit der Textstruktur (Ltext) abgelegt. Diese Texte können dann in eine Liste eingekettet werden. Kettet man dann nacheinander alle drei wieder aus, erhält man sie in umgekehrter Reihenfolge. (In der Bildschirmausgabe wurden Zeilennummern hinzugefügt.)
Die Listen im Lifo-Typ sind die grundlegenden Listen. Sie sind zwar einfach in der Programmierung und der Handhabung, aber sie werden nur selten gebraucht, da es nur wenige Anwendungsfälle gibt.
Ein Tip zur Programmierung ist hier angebracht. In den meisten Fällen verwenden die Funktionen Zeiger zum Zugriff auf Strukturen. Der Operator "->>" wurde gerade dafür geschaffen. Man könnte nun komplexere Zugriffe durch mehrfache Verwendung des Zugriffsoperators hintereinander erreichen. Trotzdem sollte man immer nur einen Schritt auf einmal machen und bei Bedarf Hilfsvariablen einführen. Die Vorstellungskraft könnte sonst überstrapaziert werden.
Sehen wir uns nun die nächste Listenart an. Der wesentliche häufiger verwendete Listentyp sind Fifo-Listen (first in - first out). Diese Listen verwalten die Elemente wie ein Puffer.
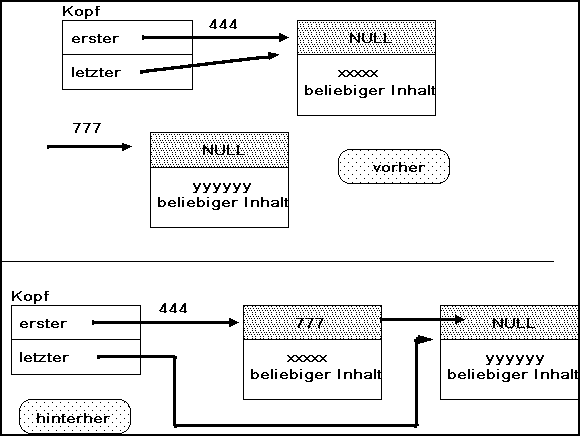
Bild 4-10: Fifo-Liste: Einhängen eines Elementes
Mit ihnen kann man eine Vielzahl von höheren Mechanismen programmieren. Stellen Sie sich als Beispiel einen Botschaftenmechanismus zwischen zwei Programmen vor. Das eine Programm sendet in unterschiedlichen Abständen Botschaften, und das andere Programm möchte sie in der gleichen Reihenfolge empfangen, wie sie abgesendet wurden. Hierzu kann eine Fifo-Liste verwendet werden, die die Botschaften wie in einem Puffer verwaltet.
Die Fifo-Listen erfordern mehr Verwaltungsaufwand. Wir benötigen nun zwei Zeiger im Anker: ein Zeiger zeigt auf den Beginn der Liste, ein zweiter auf das momentane Ende. Außerdem benötigen wir eine Spielregel, an welchem Ende wir einfügen und an welchem Ende wir Elemente entnehmen. Am einfachsten geht es , wenn wir am Ende anfügen und am Anfang entnehmen.
Bild 4-11: Informationsdatei für Fifo-Listen
Die Funktionen müssen nun den Sonderfall berücksichtigen, daß die Liste leer ist. Beim Einfügen setzen wir beide Zeiger im Kopf auf das neue Element, bei Aushängen geben wir NULL zurück. Weiter führen wir nun einen Zähler im Listenkopf mit, um bei Bedarf jederzeit die Anzahl der momentan verwalteten Elemente abfragen zu können.
Bild 4-12: Implementierung der Fifo-Operationen
Um einen einfachen Vergleich mit der Lifo-Liste zu ermöglichen, verwenden wir das bisherige Demonstrationsprogramm noch einmal und passen es nur an die Fifo-Funktionen an.
Bild 4-13: Verwendung der Fifo-Liste
Die Ausgabe am Bildschirm entspricht nun der Fifo-Regel. (Evtl. Zeilennummern wurden hinzugefügt.)
Bild 4-14: Ausgabe der Fifo-Demonstration
Bild 4-15: Aufbau des Elementes in der Sortierliste
Das Element, das in der sortierten Liste verwaltet werden soll, wird zur Demonstration wieder einfach aufgebaut. Wie in den bereits besprochenen Listen soll ein Text den Nutzinhalt darstellen. Als Verwaltungselement wird wieder an den Anfang die bekannte Struktur Elever gesetzt.
Die Funktionen, die für das Listenelement definiert werden, bestehen aus einer Initialisierungsfunktion, die immer benötigt wird, einer speziellen Vergleichsfunktion zweier Elemente für die Verwaltung in der Liste und einer Druckfunktion, die uns beim Testen gute Dienste leisten wird.
Bild 4-16: Typdefinition für sortierte Listen
Der Aufbau der sortierten Liste ist etwas schwieriger als bisher. Neben den üblichen Zeigern auf das erste und letzte Element der Liste speichert der Kopf noch zwei Funktionsadressen. Diese beiden Adressen sind die Adressen der oben erwähnten Vergleichs- und Druckfunktionen.
Die wichtigste Funktion der sortierten Liste ist das Einhängen. Schließlich muß innerhalb der Funktion zum Einhängen eines Elements die richtige Position gefunden werden. Hier werden wir dann die Vergleichsfunktion benötigen.
Sehen wir uns zuerst die Funktionen an, die zum Element gehören.
Bild 4-17: Operationen des Elements
Alle drei Funktionen sind einfach gehalten. Zuerst müssen wir ein Element nach dem Anlegen initialisieren. Der Begriff Initialisieren ist zwar etwas mißverständlich, da eine Initialisierung eigentlich ein Auftrag an den Compiler ist und nicht als Funktionsaufruf verwendet werden sollte, aber er soll dennoch verwendet werden, um anzuzeigen, daß diese Funktion nur ein einziges Mal gerufen werden soll. Und der Aufruf soll vor der Verwendung erfolgen.
Falls möglich, wird die Initialisierungsfunktion den übergebenen Text in den Zielbereich im Element kopieren und eine Meldung über Gelingen oder Mißlingen zurückliefern.
Die Druckfunktion erhält einen Zeiger auf das auszugebende Element und druckt den textlichen Inhalt aus.
Die wichtigste Funktion für die Listenverwaltung ist die Vergleichsfunktion, mit deren Hilfe die Listenverwaltung den richtigen Platz für das Einketten ermitteln kann.
Bild 4-18: Die Operationen der sortierten Liste
Die zentrale Funktion zum Einhängen wollen wir getrennt besprechen.
Bild 4-19: Sortiertes Einhängen: das Kernstück
Die erste Funktion, die wie immmer benötigt wird, ist die Initialisierungsroutine. Der Verwaltungskopf nimmt mehr Informationen auf als bisher. Die beiden zusätzlichen Informationen sind die beiden Funktionen der Elemente. Sie müssen für jede Art von Elementen getrennt erstellt werden. Schließlich gibt es keinen allgemein gültigen Aufbau der Elemente, wenn man vom immer vorhandenen Verwaltungsteil absieht. Wie eine Elementart verglichen wird oder was genau auszugeben ist, entscheiden die beiden übergebenen Funktionen.
Die Funktion zum Aushängen am Anfang der Liste ähnelt stark dem Aushängen der Fifo-Liste.
Neu könnte eine Funktion sein, die sucht, ob ein bestimmtes Element schon einmal in der Liste vorhanden ist, oder auch ein möglichst ähnliches findet. Die Implementierung dieser Funktion soll dem Leser überlassen bleiben.
Eine wichtige Funktion für die Testphase ist das Ausdrucken der in der Liste vorhandenen Elemente. Schließlich sind dynamische Vorgänge bedeutend schwieriger zu testen als fest strukturierte. Die Druckfunktion beginnt beim ersten Element der Liste und zeigt zuerst die Adresse des auszugebenden Elements an. Danach wird die Ausgaberoutine für das jeweilige Element gerufen. Die Adresse der elementspezifischen Ausgabefunktion wurde bei der Initialisierung des Listenkopfes abgespeichert.
Um die Ausgabe lesbarer zu machen, löscht die Ausgabe zuerst den Bildschirm und wartet am Ende auf einen Tastendruck des Benutzers.
An "SortEin()" werden Zeiger auf den Listenkopf und ein einzuhängendes Element übergeben. Als Elementzeiger dient ein "Zeiger auf Elever", da die Verwaltung immer der erste Bestandteil jedes Elements ist. Beim Einhängen müssen nun einige Sonderfälle berücksichtigt werden.
Der erste spezielle Fall ist eine leere Liste. Die Bedingung kann man an einem leeren Zeiger auf das erste Element der Liste erkennen. In diesem Fall setzen wir beide Verwaltungszeiger (erster und letzter) auf das neue Element und setzen den weiterführenden Zeiger im neuen Element auf NULL.
Gibt es wenigstens ein Element in der Liste, muß ein Vergleich stattfinden, ob das neue Element vor oder hinter einem bereits vorhandenen Element einzuketten ist. Dazu sucht sich die Funktion ein Referenzelement. Das Referenzelement gilt als gefunden, wenn es ein größeres Element gibt als das einzuhängende. Um das herauszufinden, brauchen wir die Vergleichsfunktion, die zusammen mit der Druckfunktion in der Initialisierung übergeben wurde. Findet die Suchschleife ein größeres Element, kann die Suche abgebrochen werden und die Funktion kann beim Einhängen weitermachen. Findet sich kein größeres Element, wird die Suche in der Zeile 22 dann abgebrochen, wenn die Schleife am Ende der Liste angekommen ist. Das Erkennungsmerkmal ist ein leerer Zeiger auf das Folgeelement.
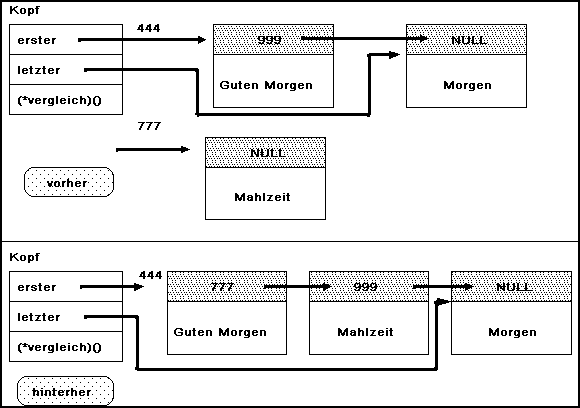
Bild 4-20: Einhängen in eine sortierte Liste
Beim Einhängen (ab der Zeile 23) werden nun wiederum mehrere Fälle unterschieden. Konnte kein größeres Element gefunden werden, dann hängt man das neue Element an das Ende der Liste an. Dabei wird der Zeiger auf das letzte Element im Verwaltungskopf neu gesetzt.
Können wir ein größeres Element finden, dann muß die Funktion wieder zwei Fälle unterscheiden. War es bereits das bisher erste Element , das größer war, dann muß das Einhängen im Kopf berücksichtigt werden.
Wurde ein größeres Element innerhalb der Kette entdeckt, dann hilft ein Hilfszeiger auf das vorgegangene Element beim Einhängen. Der Hilfszeiger ist notwendig, da die Funktion erst nach einem Vergleich den größeren finden kann.
Mit der sortierten Liste kann man sehr effiziente Sortiervorgänge programmieren. Solche Listen sind immer dann vorteilhaft, wenn die Daten langsam entstehen, wie es z. B. bei einem menschlichen Benutzer der Fall ist. Aber auch bei größeren Datenmengen spielen sortierte Listen den großen Vorteil aus, daß nur Zeiger bewegt werden. Die Vergleichsfunktionen können oft sehr effizient arbeiten. In vielen Fällen, wie unserem Textvergleich, reicht oft schon der erste Buchstabe eines Textes aus, um einen Unterschied zu finden. Nur bei sehr ähnlichen Texten wird der Vergleich länger.
Die Programmierung von Listen ist sicher keine einfache Arbeit. Dem Leser kann daher nur empfohlen werden, die Beispiele nachzuempfinden und so weit als möglich von der Testfunktion (debug) Gebrauch zu machen. Oft sieht man bei kleinen Schritten den Zusammenhang wachsen.
Dazu wird man zweifach verzeigerte Listen einführen müssen, die in jedem Element sowohl einen Verweis auf das folgende wie auch einen Verweis auf das vorhergegangene tragen müssen.
Holt man nun wieder Daten aus dem Puffer, dann werden die zuerst gespeicherten Daten als erste wieder ausgegeben.
Im Gegensatz zu den Listen könnte der Pufferspeicher auch im Programm fest angelegt werden. Ein Beispiel für den Pufferspeicher finden wir im DOS-PC zwischen der Tastatur und dem laufenden Programm. Die Unterbrechungsroutine der Tastatur trägt solange Zeichen in den Tastaturpuffer ein, wie Platz zur Verfügung steht (16 Bytes). Ist kein Platz mehr frei, dann wird das Zeichen verworfen und statt dessen ein Klingelzeichen (0x07) zum Terminal gesendet.

Bild 4-21: Aufbau eines Ringpuffers
Bei anderen Betriebssystemen ist der Tastaturpuffer zumeist wesentlich größer. Meist liegt die Größe bei 256 Bytes.
Bild 4-22: Informationsdatei des Ringpuffers
Ein Ringpuffer besteht zumindest aus einem Feld aus Pufferelementen. Hier wurden char verwendet. Für dieses Feld werden zwei getrennte Indizes oder Zeiger definiert. Der eine bestimmt den Ort des nächsten Schreibens, der andere den Ort des nächsten Lesens. Im Beispiel wurden Indizes definiert. Weiter gibt ein Zähler den Füllstand an.
Bild 4-23/24: Implementierung des Ringpuffers (Teil 1 und 2)
Die Fehlerbedingungen sind ein Schreiben in einen vollen Puffer. Ein voller Puffer ist daran zu erkennen, daß die Anzahl belegter Elemente gleich der Pufferlänge ist. Umgekehrt sollte man aus einem leeren Puffer nichts lesen. Hier braucht nur der Zähler abgefragt werden.
Mit Hilfe der beiden Positionsangaben kann man nun ein zyklisches Verhalten programmieren. Wenn eine Positionsangabe das Ende des Pufferfeldes erreicht hat, dann braucht man nur den jeweiligen Index wieder auf den Anfang zu setzen.
Im Beispiel wird der Pufferbereich bei der Initialisierung der Verwaltungsstruktur dynamisch angelegt. Dies erlaubt es, Puffer unterschiedlicher Größe anzulegen.
Wie stets wurde das Problem Ringpuffer in drei Dateien gelöst. In der Informationsdatei stehen die Typdefinition und die Deklarationen der Operatorfunktionen. In einer zweiten Datei werden die Operatorfunktionen implementiert, und in einer dritten Datei werden Variable angelegt und die Funktionen aufgerufen.
Im Hauptprogramm wird eine Verwaltungsvariable rp1 angelegt. Sie enthält noch keinen Pufferbereich. Als erstes wird dann im Programm die Initialisierungsfunktion mit einer entsprechenden Größenangabe aufgerufen. Danach kann man mit der "ringpuffer_put()"-Funktion den Ringpuffer beschreiben und mit "ringpuffer_get()" wieder auslesen. Der Ringpuffer wurde fast ganz gefüllt und danach wieder geleert. Um das Programm nicht unübersichtlich zu machen, wurde auf die notwendigen Fehlerabfragen verzichtet.
In einem zweiten Durchgang wird der Puffer nun erneut gefüllt und geleert. Beim Schreiben und beim Lesen wird dabei das Ende des Puffers erreicht. Die beiden Indexvariablen für Lesen und Schreiben müssen am Ende wieder auf den Anfang springen. Mit Hilfe eines Debuggers kann man das Programm im Einzelschritt durchlaufen und sich dabei die entsprechenden Variablen ansehen.
Bild 4-24: Test des Ringpuffers
Die dynamische Auswahl von Programmteilen wird in unterschiedlichen Umgebungen angewendet. Sehen wir uns zuerst einmal eine Sprungtabelle an. Hier kann man zur Laufzeit einen Index berechnen und an Hand dieses Index eine Funktion auswählen.
Im zweiten Abschnitt der dynamischen Verzweigungen wird der Übergang von der prozeduralen Schreibweise auf eine botschaftenorientierte Schreibweise besprochen. Dieser Übergang benötigt ein Programmierer, der Programme schreiben möchte, die unter einer graphischen Benutzeroberfläche ablaufen. Außerdem bildet sie die Grundlage der OOP.
Wenn man davon ausgeht, daß nicht immer alle Zeigervariable des Feldes vorbelegt sind, sondern nur die ersten, dann ist es sinnvoll, in einem Feld immer eine Endekennung mitzuführen. Zumeist macht man dann das Feld um einen Eintrag größer, als maximal benötigt, und stellt sicher, daß der Inhalt des letzten Zeigers immer NULL ist. Dieses Verfahren haben wir auch bei der Übergabe der Parameterzeile mit argc und argv gefunden. Der letzte Eintrag in argv war immer mit NULL vorbelegt.
Es ist manchmal mühsam und unübersichtlich, in einer Definition den vollen Datentyp anzugeben. Daher wird im Beispiel (Bild 26) zuerst ein Datentyp angelegt und dieser Datentyp danach in der Felddefinition verwendet. Dadurch wird die Felddefinition einfacher in der Schreibweise. Es ist hier, wie sonst auch, wichtig, das Programm einfach lesbar zu machen. Schließlich könnte man das Programm nach einiger Zeit selbst ändern müssen und es wäre unangenehm, wenn man dann feststellt, daß das eigene Programm unlesbar ist.
Der Datentyp fuzei ist ein Zeiger auf eine Funktion, die keinen Parameter erhält und einen Zeiger auf char zurückliefert.
Bild 4-26: Arbeiten mit Sprungtabellen
Die Funktionen im Beispiel sind extrem einfach gehalten. Sie liefern jeweils nur einen Zeiger auf ihre Textkonstante zurück. Es ist wichtig, daß die Parameterschnittstelle explizit mit void angegeben wird, um eine vollständige Funktionsdeklaration (Prototyp) zu erhalten.
Bei der der Definition der globalen Sprungtabelle können die Adressen der Funktionen zur Initialisierung des Feldes benutzt werden. Der letzte Eintrag wird mit NULL initialisiert.
Das Programm liest nun einen Buchstaben ein und wandelt ihn mit einer einfachen Bitoperation auf eine Zahl. Falls die gewonnene Zahl im richtigen Bereich für den Tabellenindex liegt, gibt das Hauptprogramm eine Meldung aus. Zur Gewinnung des Ausgabetextes wird dann eine Funktion indirekt aufgerufen.
Der Operator "*" kann hier genauso benutzt werden, wie beim Zugriff auf Daten. Der Ausdruck
(*stab[x])()
bedeutet folgendes: hole aus der Tabelle stab mit Hilfe des Index x einen Wert. Dieser Wert soll indirekt benutzt werden. Man kann auch sagen, daß man mit Hilfe des Indirektionsoperators von einem Zeiger auf eine Funktion auf die Funktion selbst übergeht. Und diese Funktion, die im ersten Klammerausdruck gewonnen wurde, wird nun mit Hilfe des Operators für den Funktionsaufruf, den beiden runden Klammern hinter der Funktionsangabe, gestartet. Das Ergebnis des Funktionsaufrufes wird, um die Übersichtlichkeit zu erhöhen, in einer Hilfsvariablen abgelegt.
Die Hilfsvariable enthält nun einen Zeiger auf einen Text, also einen Zeiger auf den jeweils ersten Buchstaben. In der printf()-Funktion wird nun der ermittelte Index und der erhaltene Text angezeigt.
Da die Audrücke wegen der notwendigen Klammern recht umfangreich werden können, wurde im Beispiel Wert darauf gelegt, sowohl die Definition der Tabelle als die Verwendung des Funktionaufrufes über die Sprungtabelle in einzelne Schritte aufzuteilen. Ziel ist es, die Lesbarkeit und Verständlichkeit zu erhöhen, auch wenn eine unnötige Zuweisung an die Hilfsvariable ein kleines bißchen Laufzeit kostet.
Der entscheidende Kostenfaktor bei heutigen Computersystemen sind die verwendeten Programme und nicht mehr die Hardware. Im Zweifel sollte man daher als Programmierer immer der Einfachheit und Klarheit der Programme den Vorzug geben.
![[Programm-Hierarchie]](proghier.gif)
Bild 4-27: Programmaufbau mit Funktionshierarchie
Für alle Probleme, die sich zur Programmierungszeit in ihrem Ablauf genau bestimmen lassen, eignet sich diese Methode hervorragend. Allerdings führt sie bei Programmen mit Benutzereingaben zu sehr unflexiblen Benutzerschnittstellen. Als eher negatives Belspiel kann man hier die sogenannten maskenorientierten Programme anführen oder die Programme, die einfach eine Liste von Auswahlmöglichkeiten anbieten.
Mit dem Aufkommen der Benutzeroberflächen müssen auch die darunter laufenden Programme ganz anders geschrieben werden. Ein Programm stellt nun einen Vorrat an Tätigkeiten bereit, den der Benutzer mit Hilfe der Oberfläche auswählen kann. Der Benutzer schickt mit Hilfe der Oberfläche Befehle (oder Botschaften) an das Programm. Die Reihenfolge des Ablaufs bestimmt der Benutzer.
![[Ereignisbearbeitung]](progloop.gif)
Bild 4-28: Botschaften orientierter Aufbau
Hier kehrt sich die Rolle des Programms um. Denkt man in Funktionen, dann steuert das Programm den aktuellen Ablauf; denkt man in Botschaften, dann ist der Benutzer zusammen mit der Oberfläche verantwortlich für den Ablauf.
Will man erreichen, daß ein Benutzer seine Befehle in einer beliebigen Reihenfolge an ein Programm schicken kann, dann muß das Programm in der Lage sein, seinen internen Zustand festzuhalten und bei Bedarf unkorrekte Angaben zurückzuweisen.
Diese Problematik gibt es nicht nur bei der Bedienung von Programmen mit Benutzeroberflächen, sondern auch bei allen Programmen, die Daten analysieren. Ein Compiler muß sich durch einen beliebigen Quelltext durcharbeiten. Dabei kann er nicht die Daten, sondern nur die mögliche Struktur (oder Syntax) kennen. Solche Programme nennt man auch Automaten.
ANSI-Steuersequenzen haben einen bestimmten Aufbau. Der einzelne Steuerstring kann eine variable Länge und auch mehrere Einzelanweisungen besitzen.
![[Zustandsdiagramm, ANSI-Codes]](ansizust.gif)
Bild 4-29: Zustände und Übergänge des ANSI-Filters
Beispiele für ANSI-Bildschirmsequenzen
(siehe:ANSI.SYS/vt100)
ESC[H Cursor Home
ESC[2J Löschen des Bildschirms
ESC[6n Geräte Zustandsreport
ESC[37;44m Weißer Vodergrund/blauer
Hintergrund
Der Aufbau einer Sequenz ist einfach. Die Einleitung besteht aus einem ESC-Zeichen ("0x1b"). Danach folgt ein "[". In wenigen Spezialfällen kann auch nach dem ESC ein "=" oder ein "?" folgen. Falls notwendig werden dann Ziffern im ASCII-Code gesendet und ein Buchstabe schließt die Sequenz ab. Zahlenangaben können mehrfach auftreten, wenn sie durch einen Strichpunkt ";" getrennt sind.
Aus dieser verbalen Beschreibung lassen sich nun die Zustände ermitteln.
1) Zeichen erhalten (1)
2) ESC gefunden ([)
3) Einleitungszeichen gefunden (A)
4) Sequenz beendet (N)
Der jeweilige Zustand wird in einer globalen Variablen gespeichert. Je nachdem, in welchem Zustand sich der Automat befindet, reagiert er unterschiedlich auf das erhaltene Zeichen.
Bild 4-30: ANSI-Sequenz-Filter
Man kann sich die einzelnen Zustände dadurch ermitteln, daß man eine Sequenz Zeichen für Zeichen untersucht und sich die Frage stellt, ob sich die Art des Zeichens ändert. Jede Änderung bedeutet einen neuen Zustand.
Bild 4-31: Filterbeispiel für ANSI-Sequenzen
Der hier beschriebene Filter ist noch keine vollständige Implementierung. Es gibt Randbedingungen, die noch eingearbeitet werden müßten. So stellt sich die Frage, was man tut, wenn zwei ESC-Zeichen aufeinander folgen. Die übliche Konvention ist es, daß ein doppeltes Fluchtsymbol, das ESC-Zeichen, durch einen Filter auf eins reduziert wird.
Mit diesen Randbedingungen läßt sich ein Automat mit Hilfe einer zweidimensionalen Sprungtabelle aufbauen.
Bild 4-32/33: Aufbau der Übergänge in einem Automaten
Für die einzelnen Zustandsübergänge schreibt man dann Funktionen, die den Übergang von einem Zustand in einen anderen auf Grund eines bestimmten Ereignisses beschreiben. Das Gesamtproblem wird dabei in viele kleine Teile untergliedert.
Das Hauptprogramm erwartet hier vom Benutzer Eingaben von numerischen Ereignissen. Da die Tabelle maximal drei Ereignisse vorsieht, kann die Ereignisnummer nur zwischen null und zwei liegen. Abhängig vom momentanen Zustand wird nun über die zweidimensionale Sprungtabelle die richtige Übergangsfunktion gerufen.
Jede Übergangsfunktion kann nun den nächsten Zustand festlegen. Danach wartet das Hauptprogramm wieder auf das nächste Ereignis.
Dieses Verfahren erscheint auf den ersten Blick aufwendig und kompliziert. Das Gegenteil ist aber richtig. Zum einen wird das große Problem in kleine Bestandteile zerlegt, und zum anderen ist die Ablaufsteuerung sehr einfach zu benutzen. Wer sich einmal in einem hierarchischen Konzept in der Vielfalt der möglichen Entscheidungen verlaufen hat, weiß das sicher zu schätzen.
Ein dritter Vorteil ist die einfache Wartbarkeit. Ändert man an einer Stelle, dann bleibt die Änderung mit großer Wahrscheinlichkeit auf einen Zustandsübergang beschränkt.
Viele technische Probleme lassen sich mit dem beschriebenen Automaten sicher programmieren. Die Kommunikation mit ihren Übertragungsprotokollen ist eines der Beispiele.
Viele Datenblätter von Computer und Controllerherstellern verwenden zur Beschreibung ihrer Bausteine ebenfalls dieses Konzept der Zustandsbeschreibungen.
Weiterer Unterteilung mit weiteren Dimensionen sind zwar von der Sprache aus keine Grenzen gesetzt, trotzdem leidet bald die eigene Vorstellungskraft.
![]()